AIエージェントを使った情報検索において、「RAG(ラグ)」という概念を知っておく必要があります。
RAG(検索拡張生成)とは?
RAG(Retrieval-Augmented Generation)は、ChatGPTなどの生成AI(LLM)が「知らない情報」を外部から持ってくることで、より正確な回答をさせる仕組みのことです。
簡単に言うと、「AIに、カンニングペーパー(参考資料)を持たせてからテストを受けさせる」ような技術です。
なぜRAGが必要なのか?
生成AIには、大きく分けて2つの弱点があります。
1. 知らないことは答えられない: AIの学習データに含まれていない「社内マニュアル」や「最新のニュース」については答えられません。
2. 嘘をつく(ハルシネーション): 知らないことでも、それらしく回答(捏造)してしまうことがあります。
RAGを使うことで、AIが自分の記憶だけで答えるのではなく、「まず信頼できる資料を探し、その内容に基づいて答える」というステップを踏むため、回答の精度が劇的に向上します。
逆に言えば、ハルシネーションを一切起こさせないことを目指す場合、情報参照元を指定のファイルのみとし、そこに無い情報は「申し訳ございません。ご指定の情報は見つかりませんでした。」と答えるように設定したりします。
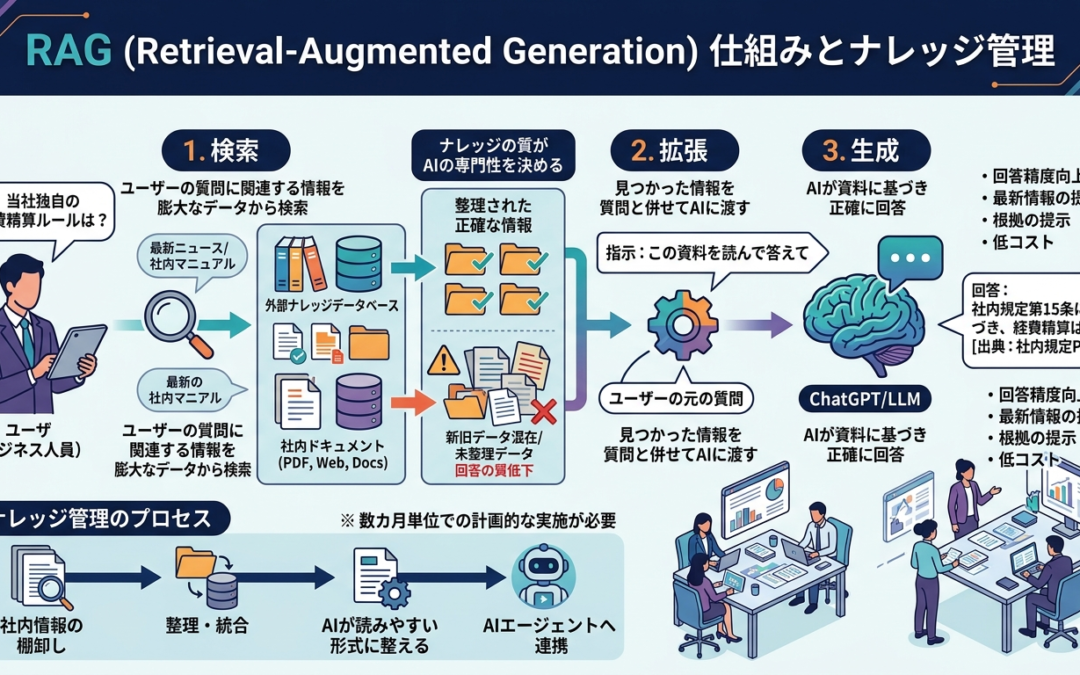
RAGの仕組み:3つのステップ
RAGは、ユーザーが質問してから回答するまでに、裏側で以下の動きをしています。
1. 検索(Retrieval):
ユーザーの質問に関連する情報を、膨大なデータ(PDF、Webサイト、社内文書など)の中から探し出します。2. 拡張(Augmentation):
見つかった情報を、ユーザーの元の質問と一緒にAIに渡します。
(例:「この資料を読んで、質問に答えて」という指示を追加する)3. 生成(Generation):
AIが渡された資料を読み込み、それに基づいた正確な回答を作成します。
RAGのメリット
* 情報の鮮度: 学習し直す必要がなく、最新の資料を読み込ませるだけで対応できます。
* コスト削減: AIをゼロから、あるいは追加で学習(ファインチューニング)させるよりも、圧倒的に安価で済みます。
* 根拠の提示: 「どの資料の、どの部分を参考にしたか」というソース(出典)を表示させやすいため、信頼性が高まります。
全自動とはいかない理由
そして、LLMが持っていない、自分達で用意する情報を「ナレッジ(Knowledge)」と呼びます。
つまり、そのナレッジ次第でAIエージェントの性質(専門性)を決めることにもなり、質の悪い情報をナレッジに指定した場合には、出てくる回答の質も低いものになるということです。
一般的な知識に関しては、LLMの方である程度持っていますが、社内情報となると、通常は持ち合わせていません。
そのため、この「ナレッジ」は自分達で社内の情報を棚卸し、整理してから、AIエージェントに渡す必要があるのです。
AIエージェント提供会社によっては、「フォルダにファイルをまとめて入れて頂ければ、あとはAIエージェントが読み取りますので・・・」と説明するケースもありますが、実際には人間側で「新旧のデータが混ざらないようにする」とか、「AIが読みやすい形式に整えてやる」といった作業が必要になってきます。
なので、それを会社全体でやるため、結構時間のかかる作業となります。
こればっかりは、お金を出して外部の会社にすべて任せるということができませんから、計画的に数カ月単位でやっていくべきこととなります。
AIエージェントを完成させるには時間がかかる?
何をもって完成とするか?という定義にもよってきますが、基本的に「社内のあらゆる情報(権限制限情報を除く)を即座に正しく答えてくれる」というものを目指した場合、満足のいくものになるまで、かなり時間かかると考えておいた方が良いでしょう。
そもそもなのですが、(検索に特化した)AIエージェントというのは、まだ発展途上の技術ということもあり、
⇒利用する
⇒ログを集計
⇒上手く答えれなかったものをピックアップ
⇒ナレッジの整理や指示文、設定変更
⇒最初に戻る
これを永遠に繰り返すことになります。
まあ、「永遠」というとオーバーですが、たとえるなら、90%答えれるようになるまで数カ月、95%までさらに1年、99%までさらに3年。。。
そんな感じで、定期的に人がログをチェックし、修正を加えていく必要があるのです。
ここは理論的に、いつまで経っても人間がタッチしないといけない部分として残り続けるでしょう。